Paperless workflow
Introduction
This is going to be quite a long post, but hopefully interesting to a particular crowd of people. I'm going to tell you all about how I have designed and built a paperless workflow for myself.
Background
This came about some months ago when I needed to find several important documents that were spread through the various organised files that I keep things in. The search took much longer than I would have liked, partly because I am not very efficient at putting paper into the files.
You could suggest that I just get better at doing that, but even if I were to do that, it still only makes me quicker at finding paperwork from the files on my shelf. If I want to really kick things up a gear, the files need to be electronic, accessible from anywhere and powerfully searchable.
The hardware
I started thinking about what I would want. Obviously a scanner was going to be the first pre-requisite of being able to digitise my papers, but what kind to get? After investigating what other people had already said about paperless workflows, it seemed like the ScanSnap range of scanners was a popular choice, but they are quite expensive and it's one more thing on my desk. Instead I decided to go for a multi-function inkjet printer - they have scanners that are good enough, and even though they're bigger than a ScanSnap, I'm also getting a printer in the bargain.
So which one to get? Well that depended on which features were important. My highest priority in this project was that the process of taking a document from paper to my laptop had to be as simple as possible, so in the realms of scanning devices, that means you need one which can automatically scan both sides of the paper.
This turns out to be quite rare in multi-function printers, but after a great deal of research, I found the Epson Stylus Office BX635FWD which has a duplex ADF (Automatic Document Feeder), is very well supported in MacOS X, and is a decent printer (which, for bonus points, supports Apple's AirPrint and Google's Cloud Print standards).
The setup of the Epson was extremely pleasing - it has a little LCD screen and various buttons, which meant that I could power it up and join it to my WiFi network without having to connect it to a computer via USB at all. I then added it as a printer on my laptop (which was easy since the printer was already announcing itself on the WiFi network) and OS X was happy to do both printing and scanning over WiFi.
I then investigated the Epson software for it and found that I didn't have to install a giant heap of drivers and applications, I could pick and choose which things I had. Specifically I was interested in whether I could react to the Scan button being pressed on the printer, even though it was not connected via USB. It turns out that this is indeed possible, via a little application called EEventManager. With that setup to process the scans to my liking (specifically, Colour, 300DPI, assembled into a PDF and saved into a particular temporary directory), the hardware stage of the project was over.
With the ability to turn paper into a PDF with a couple of button presses on the printer itself, I was ready to figure out what to do with it next.
The software
As people with a focus on paperless workflows (such as David Sparks) have rightly pointed out, there are several stages to a paperless workflow - capture, processing and recall. At this point I had the capture stage sorted, so the next one is processing.
When you have a PDF with scanned images inside it, you obviously can't do anything with the text on the pages, it's not computer-readable text, it's a picture, but it turns out that it is possible to tell the PDF what the words are and where they are on the page, which makes the text selectable. So my attention turned to OCR (Optical Character Recognition) software. I didn't engage in a particularly detailed survey because I came across a great deal on Nuance's PDF Converter For Mac product and was so impressed with its trial copy that I snapped up the deal and forged ahead. I hear good things about PDFPen, but I've never tried it.
Automation
Having a directory full of scanned documents and some OCR software is a good place to be, but it's not a great place to be unless you can automate it. Fortunately, OS X has some pretty excellent automation tools.
The magic all happens in a single Automator workflow configured as a Folder Action on the directory that EEventManager is saving the PDFs into:
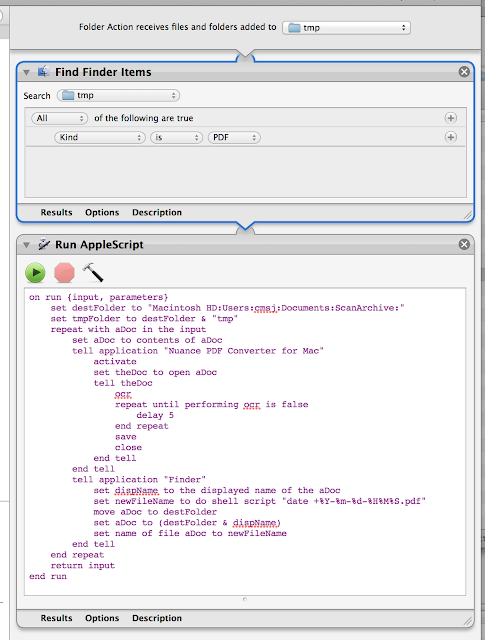
It will find any PDF files in that temporary folder, then loop over them, opening each one in Nuance PDF Converter, run the OCR function then save the PDF. The file is then moved to an archive directory and renamed to a generic date/time based filename. That's it.
That's it
Like I said, that's it. If you've been paying attention, at this point you'll say "but wait, you said there was a third part of a paperless workflow - you need tools to recall the documents later!". You would be right to say that, but the good news is that OS X solves this problem for you with zero additional effort.
As soon as the PDF is saved with the computer-readable text that the OCR function produces, it is indexed by the system's search system - Spotlight. Now all you need to do is hit Cmd-Space and type some keywords, you'll see all your matching documents and be able to get a preview. You can also open the search into a Finder window and see larger previews, change the sorting, edit the search terms, etc.
Future work
While that is it, there are future things I'd like to do - specifically I don't currently have an easy way to pull in attachments from emails, or downloaded PDFs, I have to go and drag them into the archived folder and optionally rename them. However, if you have your email hooked into the system email client (Mail.app) then it is being indexed by Spotlight, including attachments, so there's no immediate hurry to figure out a solution for that.
I do also like the idea of detecting specific keywords (e.g. company names) in the documents and using those to file the PDFs in subdirectories, but I'm not sure if I actually need/want it, so for now I'm sticking with one huge directory of everything.