The toweringly awesome Alfred 2 app for OS X has a great clipboard history browser. This is how I suggest you configure and use it:
- Map a hotkey to the viewer (I suggest making it something involving the letter V, since Cmd-V is a normal Paste. I use Cmd-Shift-Option-Ctrl V because I have my Caps Lock key mapped to Cmd-Shift-Option-Ctrl)
- Turn off the option to show snippets at the top of the Clipboard History, because snippets are a whole different thing and not relevant to pasting history
- Turn on the option to auto-paste when you hit Enter on a given item
With these options all configured, all you have to do is hit the hotkey, select the old clipboard item you want and hit Enter. It will then be pasted into the active window.
This is also useful to preview the current contents of the clipboard before pasting (which is always a good idea if you're pasting into a sensitive terminal or a work IRC channel and want to avoid spamming some random/harmful nonsense in).
The present:
It's been a very long road since Terminator 0.96 back in September 2011, but I'm very happy to announce that Terminator 0.97 was released over breakfast this morning. There's a reasonable amount of change, but almost all of it is bug fixes and translations. Here is the changelog: - Allow font dimming in inactive terminals - Allow URL handler plugins to override label text for URL context menus - When copying a URL, run it through the URL handler first so the resulting URL is copied, rather than the original text - Allow users to configure a custom URL handler, since the default Gtk library option is failling a lot of users in non-GNOME environments. - Allow rotation of a group of terminals (Andre Hilsendeger) - Add a keyboard shortcut to insert a terminal's number (Stephen J Boddy) - Add a keyboard shortcut to edit the window title (Stephen J Boddy) - Add an easy way to balance terminals by double clicking on their separator (Stephen J Boddy) - Add a plugin to log the contents of terminals (Sinan Nalkaya) - Support configuration of TERM and COLORTERM (John Feuerstein) - Support reading configuration from alternate files (Pavel Khlebovich) - Allow creation of new tabs in existing Terminator windows, using our DBus API - Support the Solarized colour palettes (Juan Francisco Cantero Hutardo) - Translation support for the Preferences window - Lots of translation updates (from our fantastic translation community) - Lots of bug fixes
My sincere thanks to everyone who helped out with making this release happen.
The future:
So. Some of you might be wondering why this release isn't called 1.0, as it was tagged for a while in the development code. The main reason is that I just wanted to get a release out, without blocking on the very few remaining bugs/features targeted for the 1.0 release. I hope we'll get to the real 1.0 before very long (and certainly a lot quicker than the gap between 0.96 and 0.97!)
However, I do think that the Terminator project is running out of steam. Our release cadence has slowed dramatically and I think we should acknowledge that. It's entirely my fault, but it affects all of the userbase.
I am planning on driving Terminator to the 1.0 release, but the inevitable question is what should happen with the project after that.
The fact is that, like the original projects that inspired Terminator (gnome-multi-term, quadkonsole, etc.), technology is moving under our feet and we need to keep up or we will be obsolete and unable to run on modern open source desktops.
There is a very large amount of work required to port Terminator to using both Gtk3 and the GObject Introspection APIs that have replaced PyGtk. Neither of these porting efforts can be done in isolation and to make matters more complicated, this also necessitates porting to Python 3.
I am not sure that I can commit to that level of effort in a project that has, for my personal needs, been complete for about 5 years already.
With that in mind, if you think you are interested in the challenge, and up to the task of taking over the project, please talk to me (email cmsj@tenshu.net or talk to Ng in #terminator on Freenode). My suggestion would be that a direct, feature-complete port to Python3/Gtk3/GObject would immediately bump the version number to 2.0 and then get back to thinking about features, bug fixes and improving what we already have.
I keep finding super handy little things to do with Alfred 2 and so I thought I'd post some more:
- Alleyoop - updates installed plugins (if the workflow author supports it, which many currently do not). I hope this will be a temporary workaround until a centralised workflow repository is created.
- Battery - shows all the vital stats of your MacBook's battery without having to run an app or a Terminal command.
- Built-in Sharing - lets you share files directly to all the social services that OS X supports.
- Paste current Safari URL - a workflow I wrote, which pastes the URL of Safari's currently visible webpage, into the application you are using. No need to flip back and forth to copy and paste the URL
- Symbols - very easy, visual way to search the Unicode tables for a symbol you're looking for (e.g. arrows, hearts, snowmen, biohazard warning signs, etc)
- TerminalFinder - lets you quickly get a Terminal for the Finder window you're looking at.
I imagine there will be more to come, the total number of workflows is exploding at the moment!
Since I started using OS X as my primary desktop, I've loved Spotlight for launching apps and finding files. I resisted trying any of the replacement apps, for fear of the bottomless pit of customisation that they seemed to offer. With the very recent release of Alfred 2, I was finally tempted to try it by the previews of their Workflow feature. The idea is that you can add new commands to Alfred by writing scripts in bash/python/ruby/php and then neatly package them up and share them with others. I was expecting to write a few myself and share them, but the user community has been spinning up so quickly that they've already covered everything I was going to write. Instead, I decided to use some time to write about the workflows I'm using so far:
- Google Search - get live results from Google as you type. It's not always what I want when I'm searching, but it's a very quick way to get some insight into the results available.
- New OmniFocus Inbox Task - Very quick way to create a new task for later triage
- Open SSH - This collects up all your hosts from SSH's known_host file, config file and local network, then opens terminal windows for you to ssh to the host you choose.
- Parallels Desktop - Easy way to start/resume your Parallels virtual machines.
- Rate iTunes Track - does what it sounds like, rate the current iTunes track.
- Screen Sharing - quickly VNC to the hosts on your network that are advertising it (including iCloud hosts if you have Back To My Mac configured)
- VPN Toggle - get on/off your corporate network quickly.
Lots more on the Alfred 2 forums. At some point it would be nice to see this unified into some kind of integrated search/download feature of Alfred 2.
Update: (2012-04-12) I've written a second post that covers a few more workflows I've discovered since this one.
If you saw my recent post on some preparatory work I'd been doing for the arrival of an LCD status panel for my HP Microserver, it's probably no surprise that there is now a post talking about its arrival :)
Rather than just waste the 5.25" bay behind the LCD, I wanted to try and put some storage in there, particularly since the Microserver's BIOS can be modified to enable full AHCI on the 5th SATA port.
I recently came across the Icy Box IB-RD2121StS, a hilarious piece of hardware. It's the size and shape of a normal 3.5" SATA disk, but the back opens up to take two 2.5" SATA disks. These disks can then be exposed either individually, or as a combined RAID volume (levels 0 or 1). Since I happen to have a couple of 1TB 2.5" disks going spare, this seemed like the perfect option, as well as being so crazy that I couldn't not buy it!
The LCD is a red-on-black pre-made 5.25" bay insert from LCDModKit. It has an LCD2USB controller, which means it's very well supported by projects like lcd4linux and lcdproc. It comes with an internal USB connector (intended to connect directly to a motherboard LCD port), except the Microserver's internal USB port is a regular external Type A port. Fortunately converters are easy to come by.
Something I hadn't properly accounted for in my earlier simulator work is that the real hardware only has space for 8 user-definable characters and I was using way more than that (three of my own custom icons, but lcd4linux's split bars and hollow graphs use custom characters too). Rather than curtail my own custom icons, I chose to stop using hollow graphs, which seems to have worked.
 The Icy Box enclosure
The Icy Box enclosure
 Ta-da! The back opens up
Ta-da! The back opens up
 Selector switch for which type of volume/RAID you want
Selector switch for which type of volume/RAID you want
 Marrying the Icy Box and the LCD. Only a small amount of metalwork required
Marrying the Icy Box and the LCD. Only a small amount of metalwork required
 Icy Box and LCD being installed
Icy Box and LCD being installed
 Finished install!
Finished install!
I've got an LCD on the way, to put in my fileserver and show some status/health info. Rather than wait for the thing to arrive I've gone ahead and started making the config I want with lcd4linux. Since the LCD I'm getting is only 20 characters wide and 4 lines tall, there is not very much space, so I've had to get pretty creative with how I'm displaying information. One thing I wanted was to show the percentage used of the various disks in the machine, but since I have at least 3 mount points, that would either mean scrolling text (ugly) or consuming ¾ of the display (inefficient). It seemed like a much nicer idea to use a single line to represent the space used as a percentage and simple display each of the mounts in turn, but unfortunately lcd4linux's "Evaluator" syntax is not sufficiently complex to be able to implement this directly, so I faced the challenge of either writing a C plugin or passing the functionality off to a Python module. I tend to think that this feature ought to be implemented as a C plugin because it makes it easier to use, but I am unlikely to bother with that because I prefer Python, so I went with a Python module :) The code is on github and the included README.md covers how to use it in an lcd4linux configuration. At some point soon I'll post my lcd4linux configuration - just as soon as I've figured out what to do with the precious 4th line. In the mean time, here is a video of the rotator plugin operating on the third line (the first line being disk activity and the second line being network activity):
Update: I figured out what to do with the fourth line:
That's another python module, this time a port of Chris Applegate's Daily Mail headline generator from JavaScript to Python. Code is on github. As promised, the complete lcd4linux config is available (also on github) here.
Update: I have moved this post to its own page, see http://www.tenshu.net/p/fake-hyper-key-for-osx.html for the latest version.
Introduction
This is going to be quite a long post, but hopefully interesting to a particular crowd of people. I'm going to tell you all about how I have designed and built a paperless workflow for myself.
Background
This came about some months ago when I needed to find several important documents that were spread through the various organised files that I keep things in. The search took much longer than I would have liked, partly because I am not very efficient at putting paper into the files.
You could suggest that I just get better at doing that, but even if I were to do that, it still only makes me quicker at finding paperwork from the files on my shelf. If I want to really kick things up a gear, the files need to be electronic, accessible from anywhere and powerfully searchable.
The hardware
I started thinking about what I would want. Obviously a scanner was going to be the first pre-requisite of being able to digitise my papers, but what kind to get? After investigating what other people had already said about paperless workflows, it seemed like the ScanSnap range of scanners was a popular choice, but they are quite expensive and it's one more thing on my desk. Instead I decided to go for a multi-function inkjet printer - they have scanners that are good enough, and even though they're bigger than a ScanSnap, I'm also getting a printer in the bargain.
So which one to get? Well that depended on which features were important. My highest priority in this project was that the process of taking a document from paper to my laptop had to be as simple as possible, so in the realms of scanning devices, that means you need one which can automatically scan both sides of the paper.
This turns out to be quite rare in multi-function printers, but after a great deal of research, I found the Epson Stylus Office BX635FWD which has a duplex ADF (Automatic Document Feeder), is very well supported in MacOS X, and is a decent printer (which, for bonus points, supports Apple's AirPrint and Google's Cloud Print standards).
The setup of the Epson was extremely pleasing - it has a little LCD screen and various buttons, which meant that I could power it up and join it to my WiFi network without having to connect it to a computer via USB at all. I then added it as a printer on my laptop (which was easy since the printer was already announcing itself on the WiFi network) and OS X was happy to do both printing and scanning over WiFi.
I then investigated the Epson software for it and found that I didn't have to install a giant heap of drivers and applications, I could pick and choose which things I had. Specifically I was interested in whether I could react to the Scan button being pressed on the printer, even though it was not connected via USB. It turns out that this is indeed possible, via a little application called EEventManager. With that setup to process the scans to my liking (specifically, Colour, 300DPI, assembled into a PDF and saved into a particular temporary directory), the hardware stage of the project was over.
With the ability to turn paper into a PDF with a couple of button presses on the printer itself, I was ready to figure out what to do with it next.
The software
As people with a focus on paperless workflows (such as David Sparks) have rightly pointed out, there are several stages to a paperless workflow - capture, processing and recall. At this point I had the capture stage sorted, so the next one is processing.
When you have a PDF with scanned images inside it, you obviously can't do anything with the text on the pages, it's not computer-readable text, it's a picture, but it turns out that it is possible to tell the PDF what the words are and where they are on the page, which makes the text selectable. So my attention turned to OCR (Optical Character Recognition) software. I didn't engage in a particularly detailed survey because I came across a great deal on Nuance's PDF Converter For Mac product and was so impressed with its trial copy that I snapped up the deal and forged ahead. I hear good things about PDFPen, but I've never tried it.
Automation
Having a directory full of scanned documents and some OCR software is a good place to be, but it's not a great place to be unless you can automate it. Fortunately, OS X has some pretty excellent automation tools.
The magic all happens in a single Automator workflow configured as a Folder Action on the directory that EEventManager is saving the PDFs into:
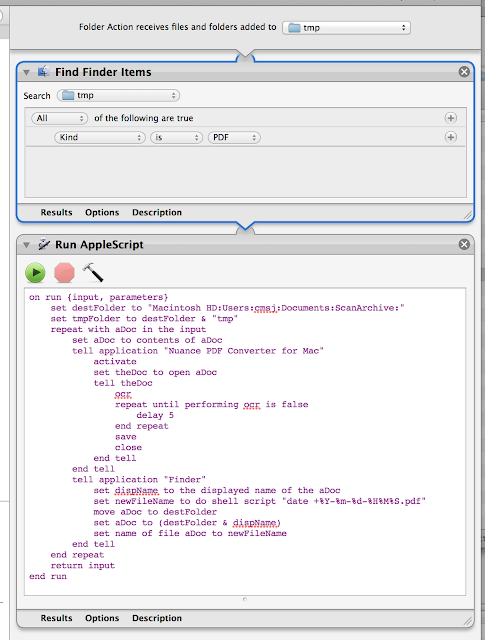
It will find any PDF files in that temporary folder, then loop over them, opening each one in Nuance PDF Converter, run the OCR function then save the PDF. The file is then moved to an archive directory and renamed to a generic date/time based filename. That's it.
That's it
Like I said, that's it. If you've been paying attention, at this point you'll say "but wait, you said there was a third part of a paperless workflow - you need tools to recall the documents later!". You would be right to say that, but the good news is that OS X solves this problem for you with zero additional effort.
As soon as the PDF is saved with the computer-readable text that the OCR function produces, it is indexed by the system's search system - Spotlight. Now all you need to do is hit Cmd-Space and type some keywords, you'll see all your matching documents and be able to get a preview. You can also open the search into a Finder window and see larger previews, change the sorting, edit the search terms, etc.
Future work
While that is it, there are future things I'd like to do - specifically I don't currently have an easy way to pull in attachments from emails, or downloaded PDFs, I have to go and drag them into the archived folder and optionally rename them. However, if you have your email hooked into the system email client (Mail.app) then it is being indexed by Spotlight, including attachments, so there's no immediate hurry to figure out a solution for that.
I do also like the idea of detecting specific keywords (e.g. company names) in the documents and using those to file the PDFs in subdirectories, but I'm not sure if I actually need/want it, so for now I'm sticking with one huge directory of everything.